基础概念积累
一、生物信息学
1 OTU(operational taxonomic units, 操作分类单元)
通过一定的距离度量方法计算两两不同序列之间的距离度量或相似性,继而设置特定的分类阈值,获得同一阈值下的距离矩阵,进行聚类操作,形成不同的分类单元。是人为给某一分类单元(品系、种、属、分组等)设置的统一标志。
1.1 OTU 的识别方法
通常按照97%的相似性阈值将序列划分为不同的 OTU ,每一个 OTU 通常被视为一个微生物物种。相似性小于97%就可以认为属于不同的种,相似性小于93%~95%,可以认为属于不同的属
1.2 OTU 表
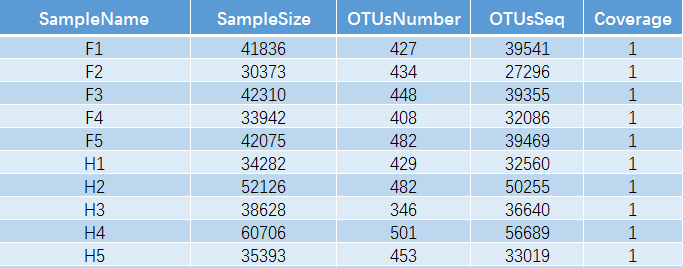
其中 SampleName 表示样本名称;SampleSize 表示样本序列总数;OTUsNumber 表示注释上的OTU数目;*OTUsSeq * 表示注释上OTU的样本序列总数。
Coverage 是指各样品文库的覆盖率,其数值越高,则样本中序列没有被测出的概率越低。该指数实际反映了本次测序结果是否代表样本的真实情况。计算公式为:C=1-n1/N 其中n1 = 只含有一条序列的 OTU 的数目;N = 抽样中出现的总的序列数目。
1.3 分类结果表
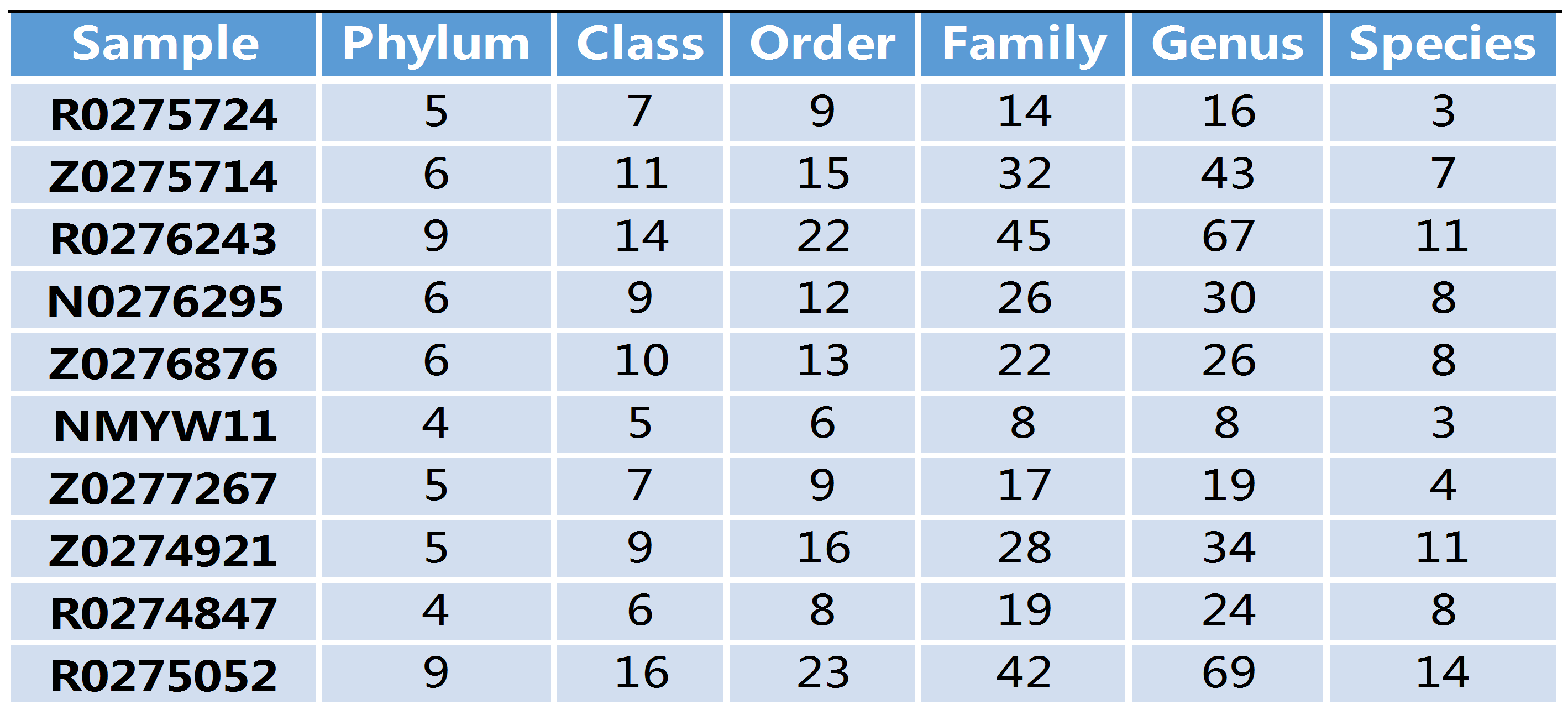
上表是对每个样本在分类字段水平上的数量进行统计,并在表中列出了每个分类字水平上的物种数目。其中 SampleName 表示样本名称;Phylum 表示分类到门的OTU数量;Class 表示分类到纲的OTU数量;Order 表示分类到目的OTU数量;Family 表示分类到科的OTU数量;Genus 表示分类到属的OTU数量;Species 表示分类到种的OTU数量。
1.4 稀释曲线
稀释曲线(或丰富度曲线)用来评价测序量是否足以覆盖所有类群,并间接反映样品中物种的丰富程度。是利用已测得 16S rDNA 序列中已知的各种 OTU 的相对比例,来计算抽取n个(n 小于测得 reads 序列总数)reads时出现 OTU 数量的期望值,然后根据一组n值(一般为一组小于总序列数的等差数列)与其相对应的 OTU 数量的期望值做出曲线来。
2 16S rRNA
16S rRNA 基因是编码原核生物核糖体小亚基的基因,长度约为1542 bp,其分子大小适中,突变率小,是细菌系统分类学研究中最常用和最有用的标志。
16S rRNA 基因序列包括9个可变区和10个保守区,保守区序列反映了物种间的亲缘关系, 而可变区序列则能体现物种间的差异。
16S rRNA 基因测序以细菌16S rRNA 基因测序为主,核心是研究样品中的物种分类、物种丰度以及系统进化。
2.1 16S rRNA 高通量测序注意事项
- 分组方式取尽量多的样本代表一个环境条件下的变异情况,样品应当有重复;
- 选择 V4 测序区段能很好反映菌群结构;
- 尽量不要使用传统的 taq 酶,容易发生复制错误。
二、生态学
1 物种丰富度(species richness)
物种丰富度是指在生态群落中不同物种的数量(无关物种丰度或相对丰度分布),一般到 OTU 水平。
2 相对丰度(relative abundance)
在生态学中,物种相对丰度是指在一定地区一定时期所调查某一种动物或植物标本的数量;对于质谱仪检测出的元素而言,相对丰度是指某离子强度相对于最大峰离子强度的百分比。
3 SHDI(Shannon’s Diversity Index,香农多样性指数)
SHDI 是一种基于信息理论的测量指数,在生态学中应用很广泛。该指标能反映景观异质性,特别对景观中各拼块类型非均衡分布状况较为敏感,即强调稀有拼块类型对信息的贡献,这也是与其它多样性指数不同之处。在比较和分析不同景观或同一景观不同时期的多样性与异质性变化时,SHDI 也是一个敏感指标。如在一个景观系统中,土地利用越丰富,破碎化程度越高,其不定性的信息含量也越大,计算出的 SHDI 值也就越高。景观生态学中的多样性与生态学中的物种多样性有紧密的联系,但并不是简单的正比关系,研究发现在一景观中二者的关系一般呈正态分布。
3.1 公式

在景观级别上等于各斑块类型的面积比乘以其值的自然对数之后的和的负值。SHDI=0表明整个景观仅由一个拼块组成;SHDI 增大,说明拼块类型增加或各拼块类型在景观中呈均衡化趋势分布。
4 QS(quorumsensing,群体感应)
微生物群体在其生长过程中,由于群体密度的增加,导致其生理和生化特性的变化,显示出少量菌体或单个菌体所不具备的特征。
5 不同多样性
主要有三种多样性指标,分别为 Alpha 多样性,Beta 多样性和 Gamma 多样性。以岛屿上的生物多样性为例,α 多样性衡量岛屿内所采每个样品(样方)内部的多样性;β 多样性衡量样品与样品之间的组成差异;γ 多样性是岛屿所有样品多样性的总和。
5.1 α 多样性
α 多样性是指一个特定区域或生态系统内的多样性,是反映丰富度和均匀度的综合指标。Apha 多样性主要与两个因素有关:一是种类数目,即丰富度;二是多样性,群落中个体分配上的均匀性。群落丰富度(Community richness)的指数主要包括 Chao1 指数(Chao1 richness estimator)和 ACE 指数;群落多样性(Community diversity)的指数包括香农-威纳多样性指数(Shannon-wiener diversity index)和辛普森多样性指数(Simpson diversity index),另外,还有测序深度指数(Observed spieces),代表 OTUs 的直观数量统计,Good’ s Coverage 指计算加入丰度为一的OTUs数目,加入低丰度影响。
Chao1:是用 chao1 算法估计群落中含 OTU 数目的指数,chao1 在生态学中常用来估计物种总数,由Chao(1984)最早提出。Chao1值越大代表物种总数越多Schao1=Sobs+n1(n1-1)/2(n2+1),其中 Schao1为估计的OTU数,Sobs为观测到的OTU数,n1为只有一条序列的 OTU 数目,n2为只有两条序列的 OTU 数目。Chao1指数越大,表明群落的丰富度越高。Ace:是用来估计群落中含有 OTU 数目的指数,同样由 Chao 提出( Chao and Yang,1993),是生态学中估计物种总数的常用指数之一。默认将序列量10以下的 OTU 都计算在内,从而估计群落中实际存在的物种数。ACE指数越大,表明群落的丰富度越高。
Ace:是用来估计群落中含有 OTU 数目的指数,同样由Chao提出(Chao and Yang,1993),是生态学中估计物种总数的常用指数之一。默认将序列量10以下的 OTU 都计算在内,从而估计群落中实际存在的物种数。ACE指数越大,表明群落的丰富度越高。
Shannon:(Shannon, 1948a, b)综合考虑了群落的丰富度和均匀度。Shannon 指数值越高,表明群落的多样性越高。
Simpson:用来估算样品中微生物的多样性指数之一,由 Edward Hugh Simpson(1949)提出,在生态学中常用来定量的描述一个区域的生物多样性。 Simpson 指数值越大,说明群落多样性越低。辛普森多样性指数 = 随机取样的两个个体属于不同种的概率 = 1 - 随机取样的两个个体属于同种的概率。
5.2 β 多样性
β 多样性指的是样本间多样性(Between-sample diversity),度量在地区尺度上物种组成沿着某个梯度方向从一个群落到另一个群落的变化率。它反映了每个组内各个样本间的群落物种组成差异。我们通过不同方法(16s 测序中,常用 Bray-Curtis、Weighted 及Unweighted Unifrac 方法,此外还有 Euclidean 和 Jaccard等)计算样本间距离可以获得样本间的 β 值,后续一般会利用PCoA(principal co-ordinates analysis)、进化树聚类等分析对此数值关系进行图形展示。
5.2.1 β 多样性图读图技巧
- PCA 图
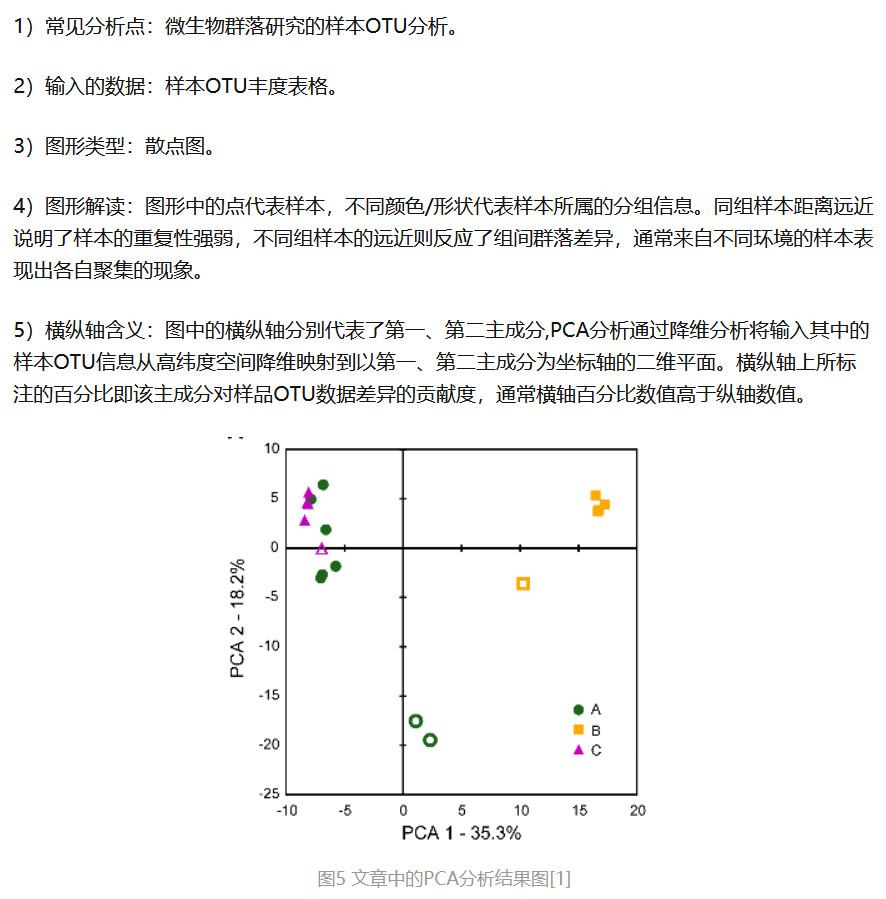
- PCoA 图
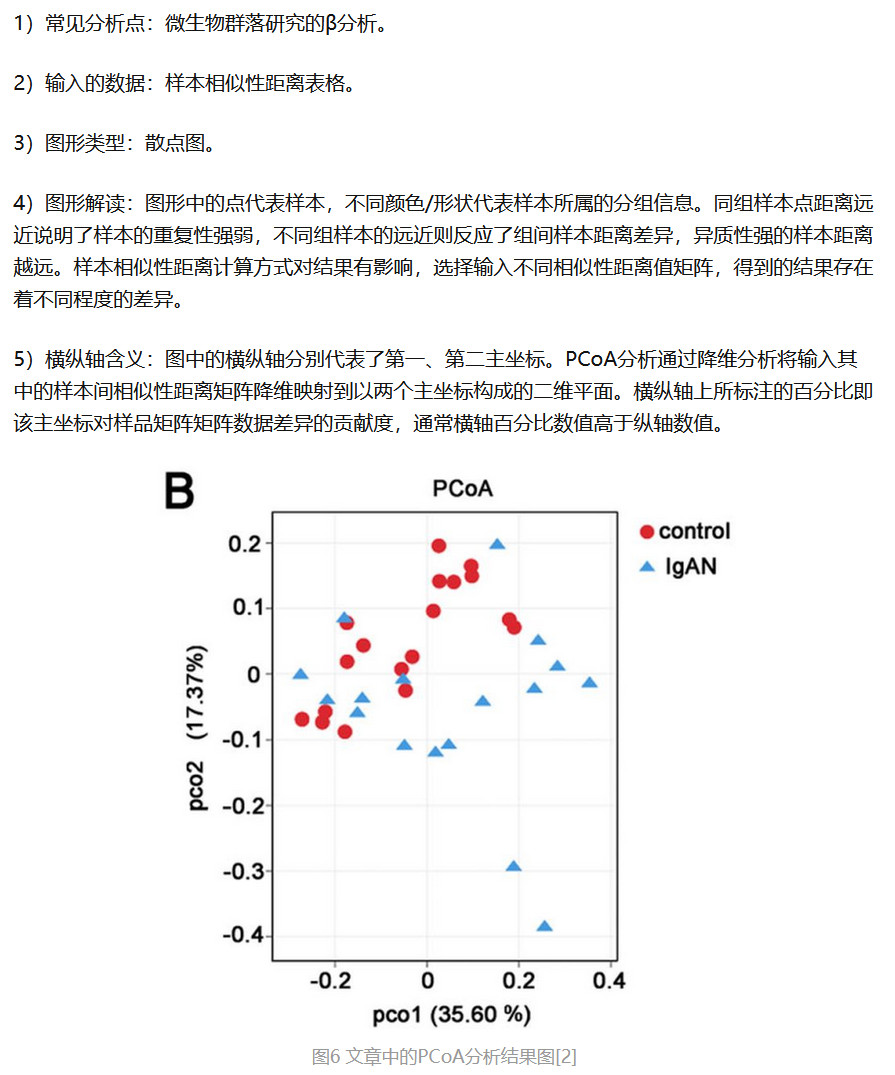
- NMDS 图
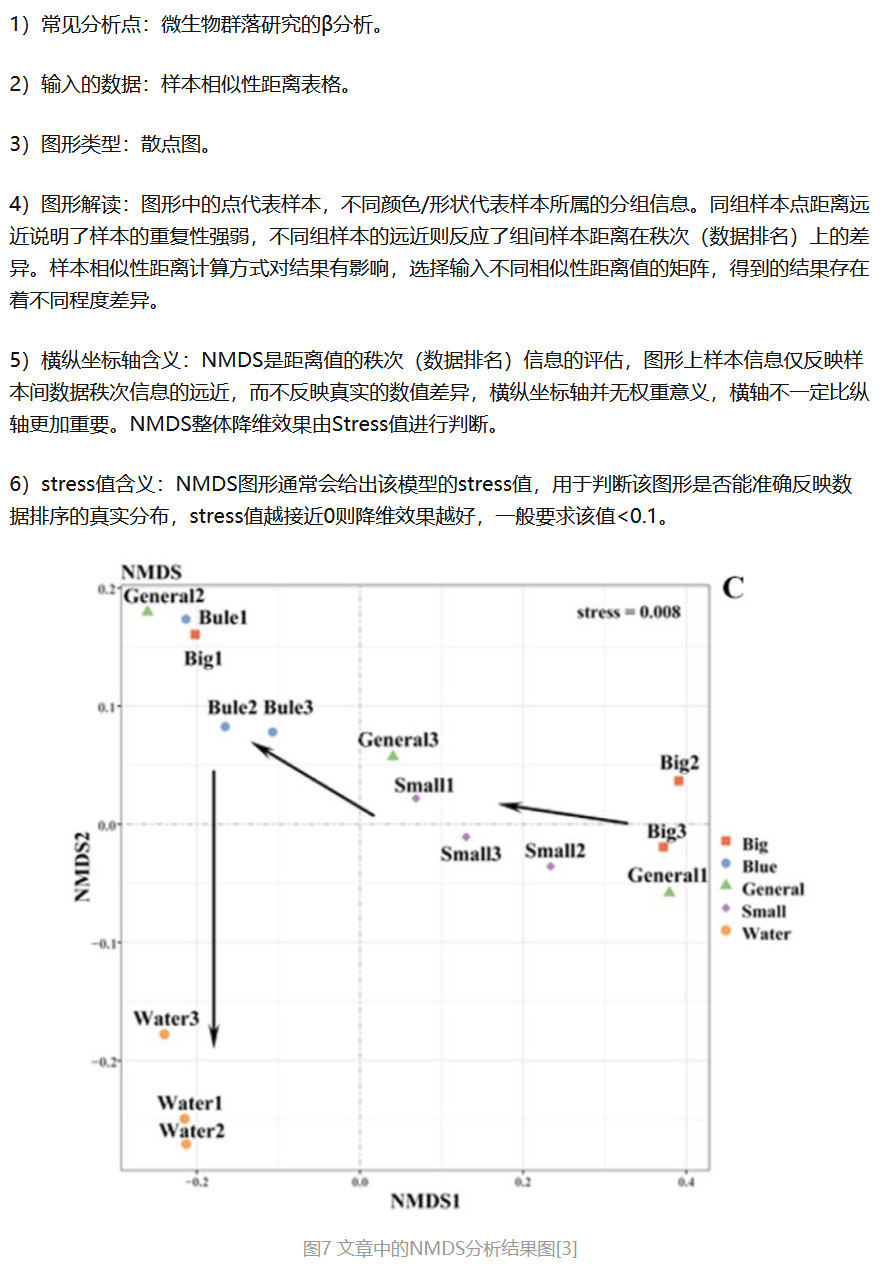
5.3 γ 多样性
将调区作为一个样点时,调区 α 多样性实际上就是所谓 γ 多样性,γ 多样性实际上是前者概念的延伸,两者仅在尺度上有差别。
6 立地(site)
立地是指造林地或林地的具体环境,即指与树木或林木生长发育有密切关系并能为其所利用的气体、土壤等条件的总和。构成立地的各个因素标准称为立地指标又称立地条件。
三、化学
1 浓度概念
表达溶液浓度时,1ppm 即为1 μg/ml;表达固体成分质量分数时,1ppm 即为 1μg/g,或 1g/t。 ppb 为 ppm 的千分之一单位,ppt 为 ppb 的千分之一单位。实际上,ppm 为 part per million 的缩写,及百万分之一,为无单位量纲,若溶液为1 μg/ml,当期密度为1 g/ml时,单位才为1 ppm,否则需要换算。
四、统计学
1 Anosim 检验
Anosim分析是一种非参数检验,用来检验组间的差异是否显著大于组内差异,从而判断分组是否有意义。R-value介于(-1,1)之间,R-value大于0,说明组间差异显著;R-value小于0,说明组内差异大于组间差异。统计分析的可信度用 P-value 表示,P< 0.05 表示统计具有显著性。对Anosim的分析结果,基于两两样本之间的距离值排序获得的秩(组间的为between,组内的为within),这样任一两两组的比较可以获得三个分类的数据,并进行箱线图的展示(若两个箱的凹槽互不重叠,则表明它们的中位数有显著差异)。

